I'm starting a short series of field notes on what builders comparing notes in the trenches are actually reaching for. First up — how we get information out of documents, because the answer everyone defaulted to for two years is quietly being challenged.
That default is RAG: chunk your documents, embed the chunks, store them in a vector database, retrieve the top-k nearest a question, and stuff them into the prompt [1]. It works, and for a while it was the reflex — the move you make before you've really looked at the problem. Lately, in the builder communities I follow, I keep seeing that reflex questioned. A recent thread captured it well: some now prefer "indexing" to RAG for speed and simplicity, others defend RAG for large enterprise corpora, a few are reaching for graphs. The useful signal isn't who won — it's that the debate is happening at all. That usually means a default is shifting.
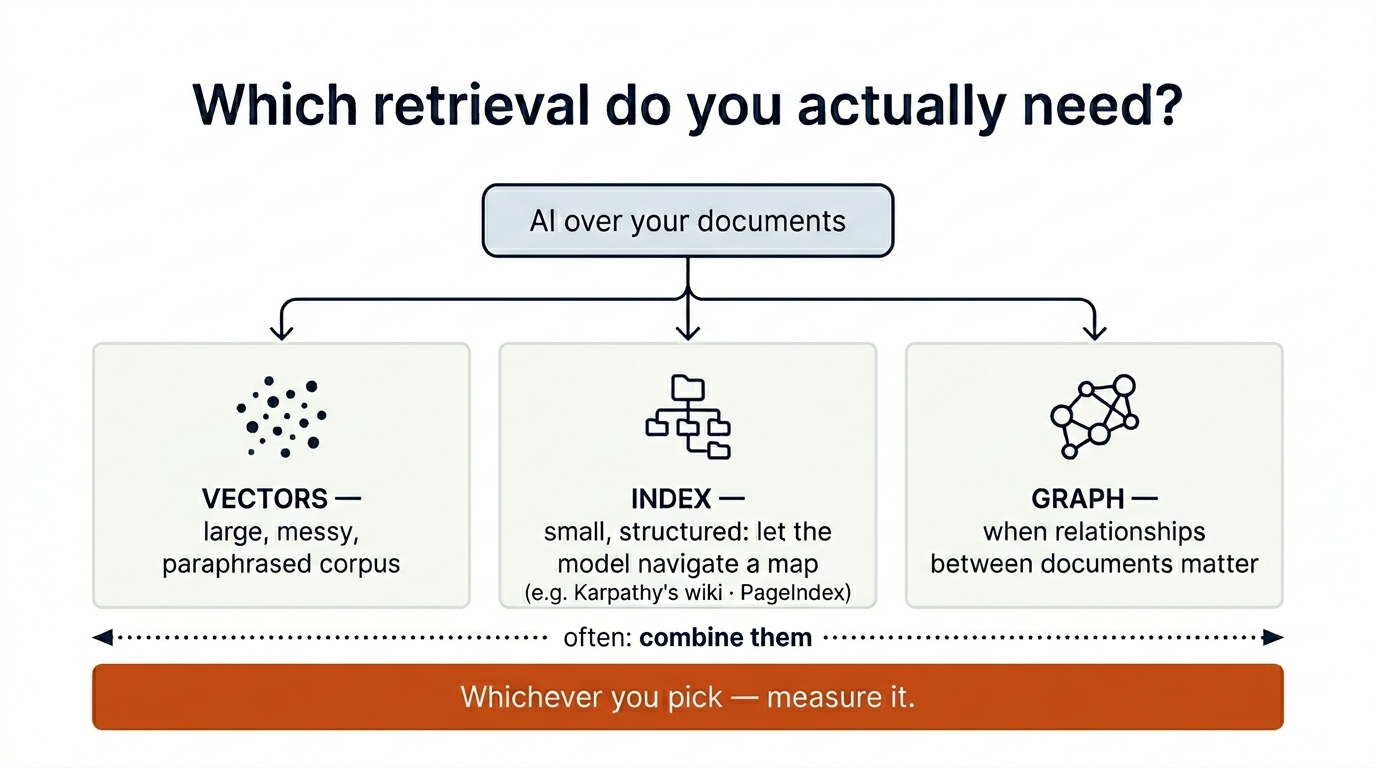
Match the retrieval method to the shape of your data — and measure whatever you pick.
What the "indexing" camp means
The most visible version of the argument came from Andrej Karpathy, whose 2026 post on "LLM knowledge bases" spread widely [2]. The idea: instead of using the model only as a chatbot, have it compile raw information into a living, interlinked Markdown wiki — articles plus an index — that it grows and reorganizes over time. His claim is that once the wiki is well-structured, you get solid multi-hop reasoning without a vector database at all: the model reads the index and the relevant pages, the way a person would.
PageIndex, open-sourced by VectifyAI, is that instinct turned into a tool [3][4]. No embeddings, no chunking — it builds a hierarchical table-of-contents tree of a document and lets the model reason its way down it: pick the chapter, then the section, then answer with a citation. The approach is explicitly inspired by AlphaGo's tree search. On FinanceBench — a benchmark of real SEC filings where chunking tends to shred tables — they report about 98.7% accuracy versus roughly 50% for traditional vector RAG [5].
That reframes the whole thing in one line: vector RAG asks "what's nearest this question in vector space?", while indexing asks "where would a careful reader look?" For some problems, the second question is simply the better one.
Where vectors still win
In my enterprise consulting work I built a reusable RAG framework for regulatory change detection in energy — large, messy, multilingual corpora where a compliance team needs to catch what changed year over year. That's the home turf of vectors: millions of unstructured passages, the same obligation phrased ten ways, no clean table of contents to navigate. What made it trustworthy, though, wasn't the vector store — it was that we measured retrieval quality with tools like Ragas and Langfuse [6][7] instead of guessing.
Where I reached for vectors out of habit
Contrast a WhatsApp sales assistant I built for a retail client. "Retrieval over a product catalog," so — RAG, obviously. Except the catalog was modest and highly structured: categories, store types, shelf dimensions. The hard parts were respecting that structure and controlling cost (we migrated the vector layer from pgvector to DynamoDB + FAISS mostly for economics). In hindsight, much of that was structured lookup wearing a RAG costume — a model walking a clean index would have done a lot of it with far less infrastructure.
A way to decide
Three questions, before "which vector DB":
-
How big and messy is the corpus? Millions of unstructured, paraphrase-heavy passages point to vectors. A few hundred well-organized documents point to an index the model can navigate — easier to build and to debug.
-
Where does the answer live? If it can only be assembled by reading widely and connecting scattered mentions — "anything touching thermal limits across these reports" — that's semantic recall, and vectors are built for it. If it sits in one knowable place — "the warranty clause in the 2024 contract," "the spec sheet for product X" — that's a navigable lookup, where an index beats nearest-neighbor guessing.
-
Can you measure it? Whatever you pick, instrument it before you trust it — Tom DeMarco's old line, "you can't control what you can't measure," still applies [8]. Pick the lightest option, score its retrieval, and let the numbers tell you when to add complexity.
And often, the answer is both
The strongest systems don't pick a tribe: a cheap filter narrows the space, vectors handle semantic recall inside it, and a graph layer comes in when the relationships between documents — citations, dependencies — are the real signal. Microsoft's GraphRAG is a good reference point for that last piece [9].
Where this is heading
There's a bigger shift hiding inside the indexing idea. Once a knowledge base is something the model reads, navigates, and writes back to, you've basically described how the new agent "harnesses" work — agents that use a filesystem as a scratchpad and long-term memory instead of cramming everything into the context window. LangChain's Deep Agents make this concrete with pluggable "backends" for exactly that [10][11], and it lines up with how teams like Anthropic now describe building effective agents [12]. That convergence — retrieval and agent memory becoming the same problem — is where this series goes next.
For now, the through-line from people actually shipping: the default deserves a second look. Match the mechanism to the shape of your data, keep it as light as it can be, and measure before you add.
What are you reaching for lately — and where does it break for you? I'm collecting these field notes, so reply and tell me.
References
- Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (2020) — arxiv.org/abs/2005.11401
- A. Karpathy, "LLM knowledge base" post (2026) — x.com/karpathy/status/2039805659525644595
- PageIndex (VectifyAI), GitHub — github.com/VectifyAI/PageIndex
- PageIndex, "Vectorless, Reasoning-based RAG" — pageindex.ai/blog/pageindex-intro
- FinanceBench (Patronus AI) — arxiv.org/abs/2311.11944 · result coverage — VentureBeat
- Ragas (RAG evaluation) — docs.ragas.io
- Langfuse (LLM observability) — langfuse.com
- T. DeMarco, Controlling Software Projects (1982) — Wikiquote
- Microsoft GraphRAG — github.com/microsoft/graphrag · paper — arxiv.org/abs/2404.16130
- LangChain Deep Agents, docs — docs.langchain.com/oss/python/deepagents/overview
- LangChain, "How agents can use filesystems for context engineering" — blog.langchain.com
- Anthropic, "Building Effective Agents" — anthropic.com/research/building-effective-agents